edeposit.amqp.harvester¶
This module is used to collect public metadata about new books published by selected czech publishers.
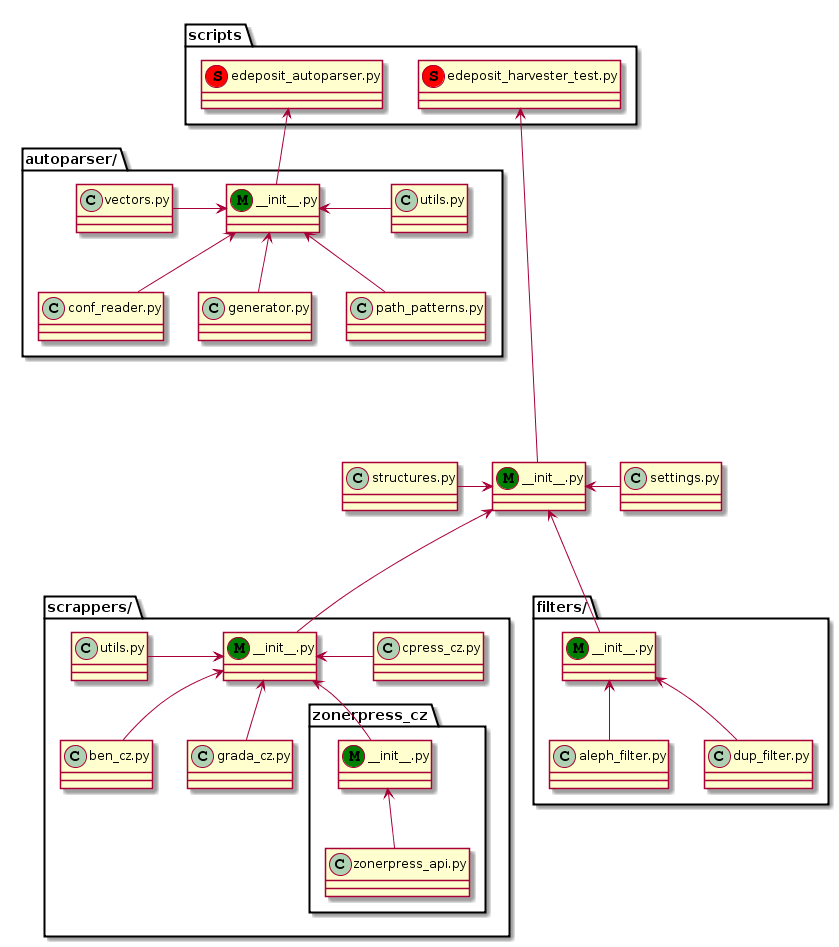
User guide / Uživatelská příručka¶
API¶
Whole module is divided into following parts:
Filters¶
Filters are then used to filter data from Scrappers, before they are returned. This behavior can be turned off by USE_DUP_FILTER and USE_ALEPH_FILTER properties of settings submodule.
Other parts¶
There are also other, unrelated parts of this module, which are used to set behavior, or to define representations of the data.
Autogenerator¶
Last submodule is Autoparser, which makes creating new parsers easier.
AMQP connection¶
AMQP communication is handled by the edeposit.amqp module, specifically by the edeposit_amqp_harvester.py script.
Source code¶
This project is released as opensource (GPL) and source codes can be found at GitHub:
Testing¶
Almost every feature of the project is tested in unit/integration tests. You can run this tests using provided run_tests.sh script, which can be found in the root of the project.